How does Viewtracker affect Confluence's performance?
Depending on the Confluence configuration and the amount of content and simultaneous user interactions, a performance loss cannot be completely ruled out. We recommend making the following two settings if you run into performance issues:
Dark feature "Batch Inserting
Batch inserting optimizes write operations by aggregating view data and storing it at one-minute intervals, rather than writing each view event individually as it occurs. Enable the batch inserting as described on this page.
Activate Caching
To improve performance, especially on high-traffic Confluence sites, enable the "Cache statistics" toggle on the settings page (as described here). This setting delays the refresh of metrics displayed in various reports by 10 minutes. While this enhancement improves performance, it also means that the data shown in Viewtracker reports will not be accurate during this 10-minute window.

Data Retention
Data Retention allows administrators to specify the duration for which Viewtracker stores analytics data. By default, all data is retained indefinitely; however, enabling this feature can improve performance on large Confluence instances and support compliance with data privacy regulations. While detailed tracking data (like searches) is permanently removed, total view counts per content item are preserved and updated. Enable Data Retention as described on this page.
Maximum Usage Report
As explained here, the number of simultaneously created Content & Usage reports is limited to 4 by default. You can adjust this limit as needed. Reducing the number of concurrent reports can improve overall Confluence performance by lowering system load and ensuring smoother operation, especially in environments with high data volumes or user activity.

Read-Only Database
The Viewtracker version 9.2.4 enables the setup of a read-only database, which can be used to generate reports. However, it currently lacks a user interface for configuring this read-only database.
In short
Viewtracker will record the tracked data into the database of the Confluence instance.
You have the option to set up an additional database that synchronizes with the Confluence instance database to retrieve all the data.
Viewtracker will then read the data from this synchronized database to generate reports.
This approach offers the advantage of not using the Confluence instance database when generating complex reports, thus ensuring no negative impact on Confluence’s performance.
Setup Guide
Set up a database that synchronizes with the production Confluence database.
Follow the procedure described here for configuring a datasource with the additional step listed with the letter “e”.
If not already present, add the database driver
Configure the datasource in Tomcat
You must set 'jdbc/ViewtrackerDataSource' as the Viewtracker-specific resource name in
<installation-directory>/conf/server.xml.
Configure the Confluence web application
Set 'jdbc/ViewtrackerDataSource' as
<res-ref-name>in<CONFLUENCE_INSTALLATION>/confluence/WEB-INF/web.xml.
Enable the Viewtracker app’s read-only data source look-up by adding the following line to the
<installation-directory>/bin/setenv.shfile:CODECATALINA_OPTS="-DViewtrackerReadOnlyDataSourceLookupEnabled=true ${CATALINA_OPTS}"
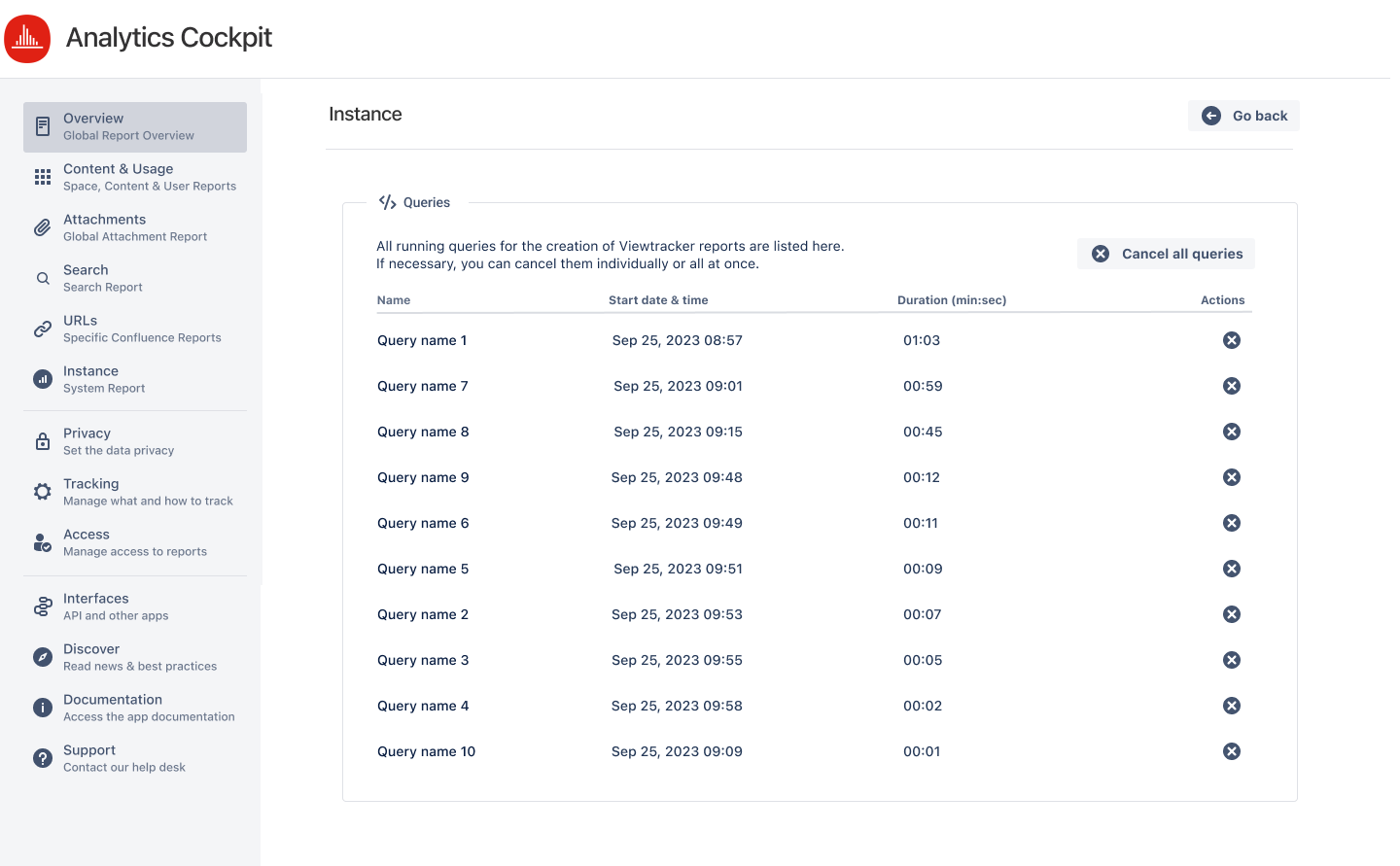
Stopping Queries
Use the “View Queries” feature to monitor all currently running Viewtracker queries that generate reports. The list updates every 30 seconds and shows each query’s name, start time, duration, and available actions. Administrators can cancel individual queries or terminate all running queries simultaneously to optimize system performance. Enable this feature as described here. While not preventive, this measure can effectively address and unblock reports that are stuck in continuous cycles.
Need Help Diagnosing Performance Issues?
If you're experiencing performance issues and are unsure of the cause, you can generate and send us the bv Support ZIP file as described here. This file contains diagnostic information that helps our support team analyze and identify potential issues in your setup. We'll review the contents and get back to you with our findings as soon as possible.